A note about Edward Gibson, an important witness involved in prosecuting Jacobite prisoners
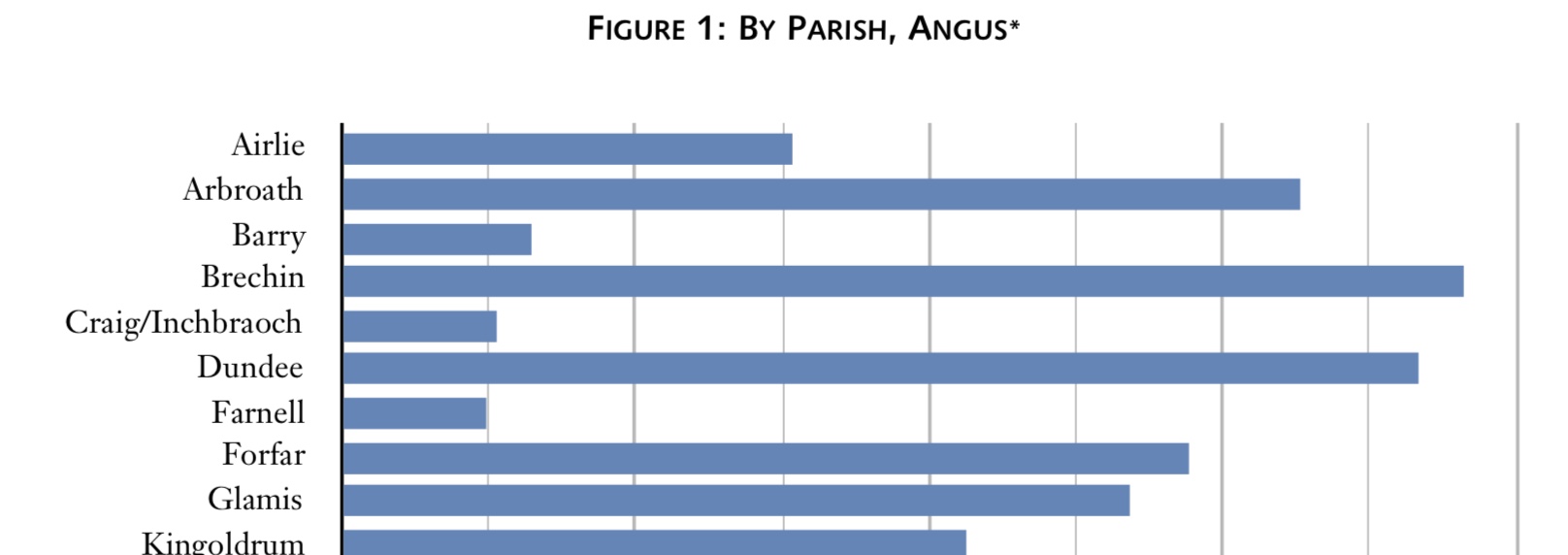
To reinforce our recent discussion of critical thinking about the historical data used within a project like JDB1745, this week’s post illustrates an example of that application in action. While looking through some of the published trial records related to government prosecution of the Manchester regiment, team member Bill Runacre found a data conflict that took a bit of detective work to iron out. In the 1816 trial transcript of Captain James Bradshaw, published in Vol. XVIII of Howell’s (or Corbett’s) State Trials, amongst the witnesses who took the stand against the Manchester officer was one Henry Gibson, allegedly a soldier in Elcho’s Jacobite cavalry troop. Some character notes about Gibson are described within the transcript:
Henry Gibson was also produced and sworn, who said, That he himself was unfortunately seduced into the rebel army, and entered into lord Elcho’s troop of horse-guards; that the prisoner, Mr Bradshaw, marched with them as a private man in the said corps; that the troop was drawn up at the battle of Culloden, and that he there saw the prisoner on horseback in the said troop, with pistols, and a broad sword by his side, and a white cockade, and that he continued with the said troop till he was taken prisoner by his royal highness the duke of Cumberland’s army.1
Much of Gibson’s testimony against Bradshaw sounds quite similar to that of dozens of other witnesses brought in to inculpate suspected Jacobite prisoners in the years following the failure of the final rising. Pertinent details which the government found most helpful often included firsthand descriptions of the defendant’s presence within the Jacobite army and specific duties in that station, persons of repute with whom they were seen conversing, and the identification of clothing and arms that were worn during their tenure in Jacobite service. The collective depositions by Gibson and those of at least eight other witnesses were enough to condemn James Bradshaw, and he was thus found guilty and subsequently executed in London on 28 November 1746. As it turns out, however, Henry Gibson did not actually exist.