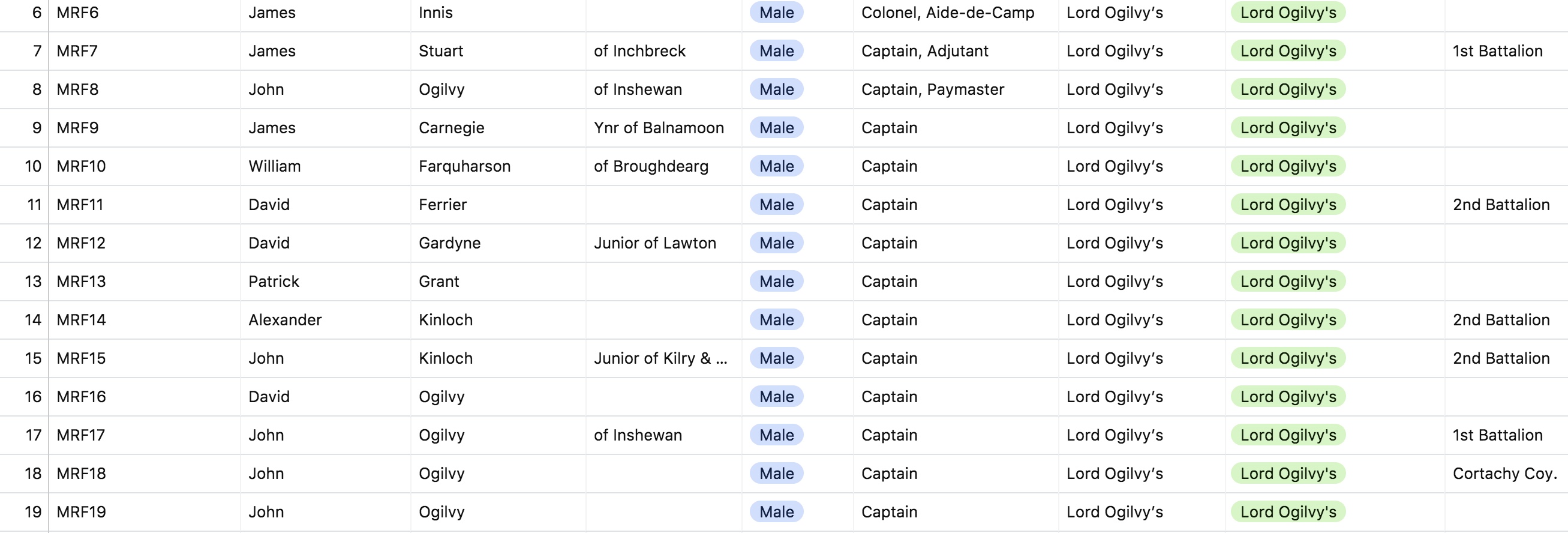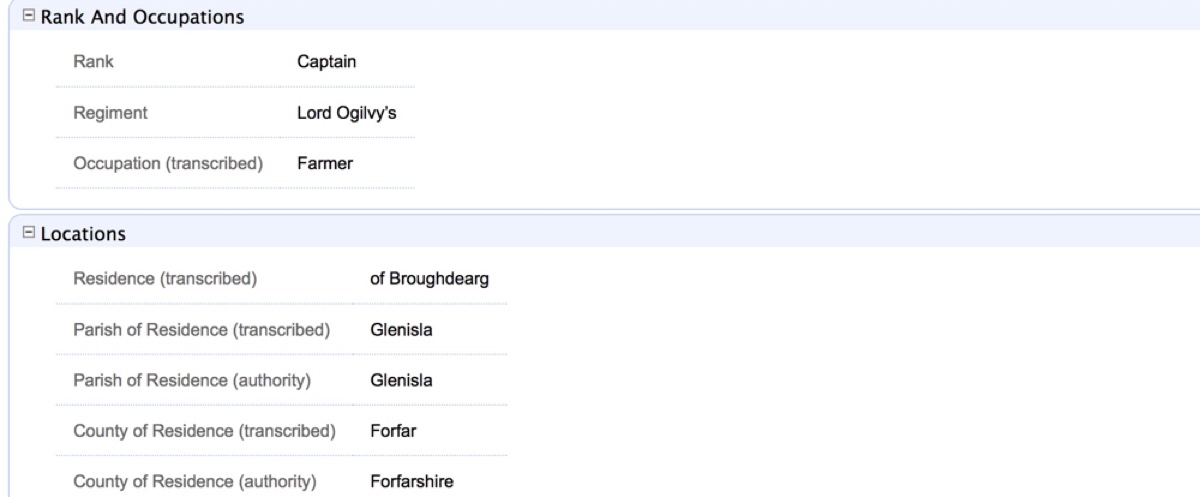
An example of place-name authority usage within JDB1745.
In last week’s post, we set out to introduce the value of a historical database by thinking critically about historiographical and biographical data related to the Forfarshire Jacobite regiment lead by David Ogilvy in 1745-6. While this may seem like a straightforward prerequisite, a comprehensive survey of both primary and secondary sources that address the constituency of this regiment presents a labyrinthine paper trail that requires us to carefully scrutinize the information heretofore recorded. Getting a firm grasp of this ‘lineage’ of data is essential to upholding the accuracy of what is finally entered into our database.
As we suggested last week, simply copying biographical information from published secondary- and tertiary-source name books or muster rolls is not enough to ensure that the data is accurate or even relevant. In short, this practice is ‘bad history’ and opens up the analysis to errors, inconsistencies, and others’ subjective interpretations of primary-source material. In the effort to combat this, we need a methodology that maintains the integrity of the original sources as much as possible while still allowing us to convert them into machine-readable (digital) format. Part 2 of this technical case study will demonstrate one possible method of doing this.
When we discuss the term ‘clean data’, we are referring to information that is transcribed into digital format with as little subjectivity as possible. This means misspellings and known errors from primary sources are left intact, conflicting evidence from disparate documents is retained, and essentially no liberties are taken by the modern historian or data entry specialist to interpret or otherwise blend or ‘smooth out’ information upon entry. Though it might seem unwieldy to use raw data with so many chaotic variables, it would be fundamentally distorting the results to do otherwise.1 As long as we take the time to set up an effective taxonomy for transcribing (now) and analyzing (later) our data, the results will be well worth the extra care.